这次记录的是泛型和容器,有点相爱相杀的感觉。
泛型
在写泛型,我们先回忆八大基本数据类型和引用数据类型。它们都可以做参数的数据类型和方法的返回类型。有没有一种数据类型可以解决重载时代码的冗余呢?那就是我们最喜欢的Object类,它是所有类的超类(父类),根据多态的特性,很好解决了重载代码的冗余,我们先实验以下。
1 | public class OTest { |
我们在放数据的时候挺轻松的,整数,字符,布尔,小数,往里放就行,但是,取数据却要每次从Object类转为相应数据类型的包装类。如果我定义的是这个数组呢,一千一万,每次取都要很麻烦,浪费时间。
所以就有了泛型,不仅解决了重载代码的冗余,也解决了类型转换的问题,也定义了一种规范吧。
泛型类
1 | public class genericTest { |
可以看到,我们只是在类加了
1 | public class genericTest { |
泛型抽象类和接口
现在想想,既然有泛型类,那么抽象类、接口呢?它们也是类,所以它们自然而然也可以泛型化。简单带过了。
1 | interface InterGeneric<T>{ //泛型接口 |
泛型方法
泛型方法一定要注意你使用的是哪个,类定义的类型,还是方法新定义的类型,而方法新定义的类型可以为任意类型,不受约束。
1 | public class genericTest { |
泛型还有一个通配符?和其他注意点,但没弄明白……
容器
我们之前也接触过容器,那就是数组,数组是有序列表,有相同的数据类型。今天我们学的是其他容器,Collection和Map。
Collection
1 | public interface Collection<E> extends Iterable<E> |
Collection实现了Iterable(迭代器)接口,可以看到,它们都是泛型类,而被继承的也都是泛型。Iterable本身最主要定义了forEach循环,迭代和循环也没多少差异。
而Collection又被哪些继承呢?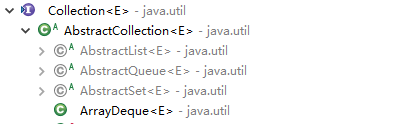
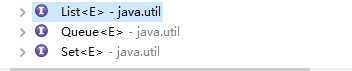
可以看到,主要的有抽象类和接口,而这些可以细分为三类List(链表)、Set(集合)、Queue(队列)。这也就是Collection所学的。
List
List被实现的主要类有ArrayList和Vector,它们都是单链表,而且方法都差不多。只是,它们和StringBuffer和StringBulder一样,Vector是线程安全的类。而它们都是单链表,学过数据结构应该都知道,还要双向链表、循环链表等等其他复杂的链表。
ArrayList
顾名思义:数组链表。它是由数组实现的。看看以下原代码。
1 | private static final int DEFAULT_CAPACITY = 10; |
第一块是整型常量,大小为10。第二块定义一个Object[]数组,那个transient不知道谁啥,但也不影响我们看代码。再看最后两个构造方法。如果使用的是默认构造方法或给的值为0,则Object数组大小为10,或者指定它的大小,但小于0,抛出异常。
以下则是声明ArrayList,容量为10
1 | import java.util.ArrayList; //别忘了引入相应的包 |
如果把容器大小变为-10,则编译报错
学容器或学数据结构或java学的是啥,都是为了数据的增删改查。
增加元素,链表在C语言的数据结构中,可以在链表范围内随意增加一个元素,那么链表如何呢?
1 | import java.util.ArrayList; |
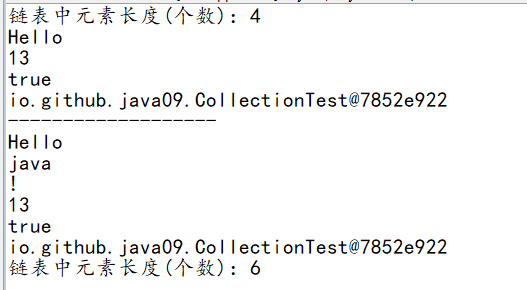
我们可以发现,定义带链表长度是5,但是我们输入了六个元素,没有报数组越界,那是因为在ArrayList中,每次添加一个元素,都进行了判断,如果超过指定的范围,则给它的范围扩容,从新copy一个新数组给原有的数组。
1 | int newCapacity = oldCapacity + (oldCapacity >> 1); |
这是它扩容的其中两行代码,每次扩容原数组的一半,把值复制给扩容后的数组,但变量名还是原数组名。
在链表中,没有删除这个方法,只有remove()方法,移除元素,所以它们虽然不在容器里,但还在内存上。
1 | import java.util.ArrayList; |
链表添加到某个位置的元素和删除某个位置的元素,都是在数组里“整体来回移动”得到的,也就是顺序表。所以它修改和查找某个元素是最方便的
修改和查找提下方法
1 | set(index, element) 设置元素值,下标名,新的元素值。 |
我们还应该遍历元素,有for循环遍历,也有容器特有的迭代器遍历。
1 | for(int i=0; i<list.size(); i++) { |
ArrayList就讲那么多,而Vector的方法很多都一样,无非加了线程安全。当然还有其他方法,很多方法Arrays就接触过,虽然可能结果不同,但意思是差不多的。
Stack
Stack是Vector的一个子类,我们称为栈,栈的特性就是先进后出,后进先出,就像羽毛球桶一样,先放进去的最后拿出来。理解它,递归也就差不多想通了。
1 | import java.util.List; |
Queue
Queue是一个接口,也继承了List接口,而实现它全部方法的类主要有LinkedList(一开始找队列的类没找到,没想到在java名字不一样),我们常用的队列就是LinkedList。它的特点是先进先出,后进后出,就像买票一样,先到先得。
1 | import java.util.LinkedList; |
Set
集合,在集合里元素是无序的,不能有重复的值。而链表则是有序,可以有重复的值。因为继承的是在是太多了,这里找了个HashSet类学习。
1 | import java.math.BigDecimal; |
可以看出,我们存入的和打印出来的位置不一样,因为在Set是无序的,也不知道它具体怎么排列的,好像是字符串优先。
而且,如果存入的数据类型和值一样,则集合只存一个,即使它们地址不同值相同,也只存一个值。
Map
Map原本的意思是地图,当然,在这不是这个翻译,它翻译为映射。它里面有两个泛型,一个是键(Key),另一个是值(Value),就好像我们的书或字典,键就是目录的序列,值就是该序列下具体的内容。所以有的语言也称它为字典。
HashMap
应该是最常用的Map,也是最基础的,它里面有两个值<Key,Value>。我们通过找Key(键),来获取(Value)值,键在值在,键亡值亡
1 | import java.util.HashMap; |
看到在容器这里,应该就能体现面向对象的优越性,因为子继承父类,而父类可能继承其他类或其他接口,这样下来,子类很多方法的用法都是差不多的。会一个,其他看看就会用了。
而泛型呢?一开始说相爱相杀呢?无论是Collection
泛型和容器的记录就到这,有错请在下方提出问题。

